When it comes to performing data management and data analysis (or analytics), especially on big data sets, data warehousing is an established solution on the market. In the last decade, however, we saw another concept successfully entering the market, offering an alternative solution for big data analytics: data lakes. Finally, during the past couple of years, there has been a lot of excitement around data lakehouses, a hybrid solution that is said to combine the best of both worlds. So which solution to choose now? Let’s see if we can find some answer to that question.
First things first: the data warehouse (DWH). This can be defined as a structured repository of data that you collect and process for analytical purposes. It is a subject-oriented, time-variant, integrated, and non-volatile collection of data. As it contains historic data around a subject, the data warehouse can be considered a single source of truth.
The data in your data warehouse is extracted from various data sources like files, databases, etc. That extracted data is then transformed and loaded to your data mart or data warehouse. In order to have meaningful data in your data warehouse, a process called ETL (extract, transform, load) is used.
The data stored in your data warehouse is analytical data which is already cleaned and processed. Thus, this data is ‘ready’ to be consumed for analytical, reporting, or visualisation purposes by your business users. These business users or data engineers access the data from your data warehouse using BI tools or SQL queries.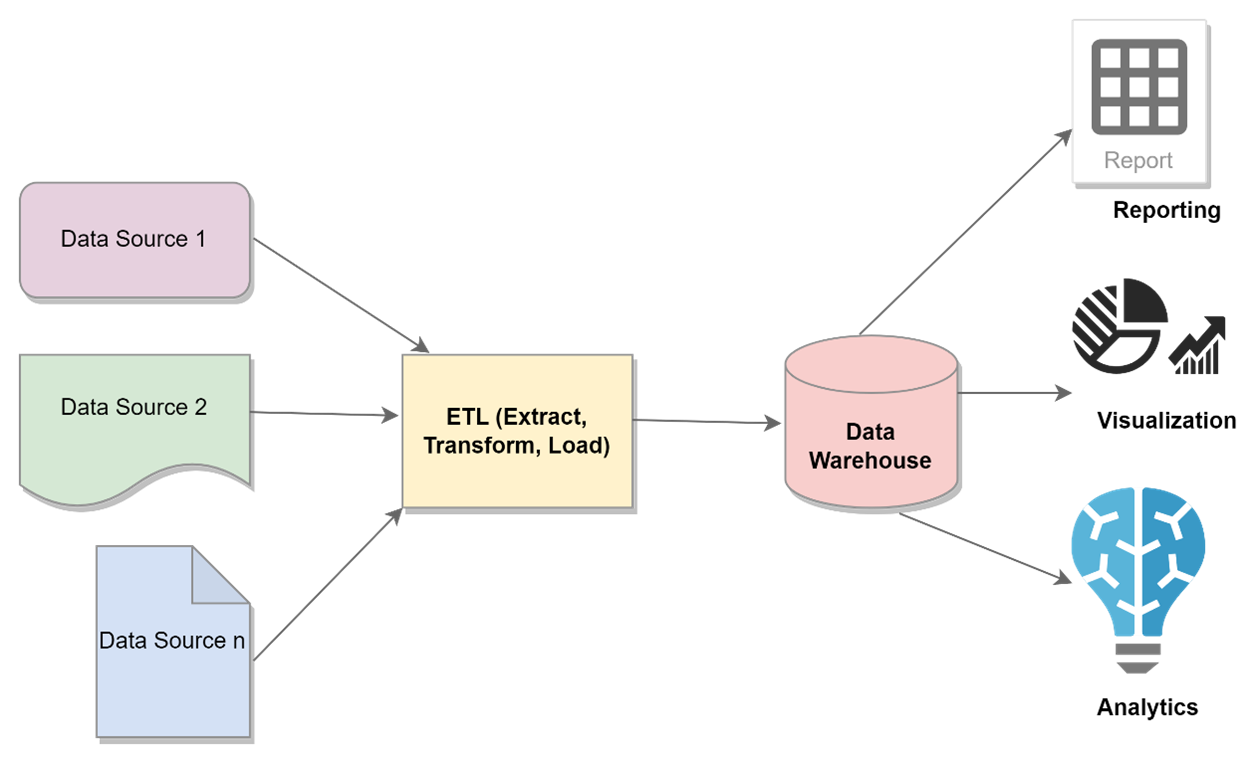
Here are some of the benefits of the data warehouse:
- It contains high-quality standardised data which is ready to be consumed.
- It contains analytical data, so it is perfect for analytics, reporting, and visualisation.
- Queries are optimised for and performance efficient in the data warehouse.
- Integrating the data is easier in a data warehouse.
There are also a couple of weaknesses to the data warehouse:
- It lacks flexibility with unstructured data such as social media and streaming data.
- It has a high implementation and maintenance cost.
The data lake: overcoming the weaknesses of the data warehouse
The data lake concept was specifically invented to overcome the weaknesses of the data warehouse. It can be defined as an extensive centralised collection of raw or unprocessed data, structured but also unstructured. Unlike the data warehouse, the subject of the data lake is undefined at the time of data loading.
A data lake is easier to maintain but the extraction of useful information from it requires expert data processing knowledge. In order to obtain useful data from your data lake, here a process called ELT is used. The data is first extracted from its source and then loaded into your data lake. This is followed by the transformation of that data based on your specific analytical needs.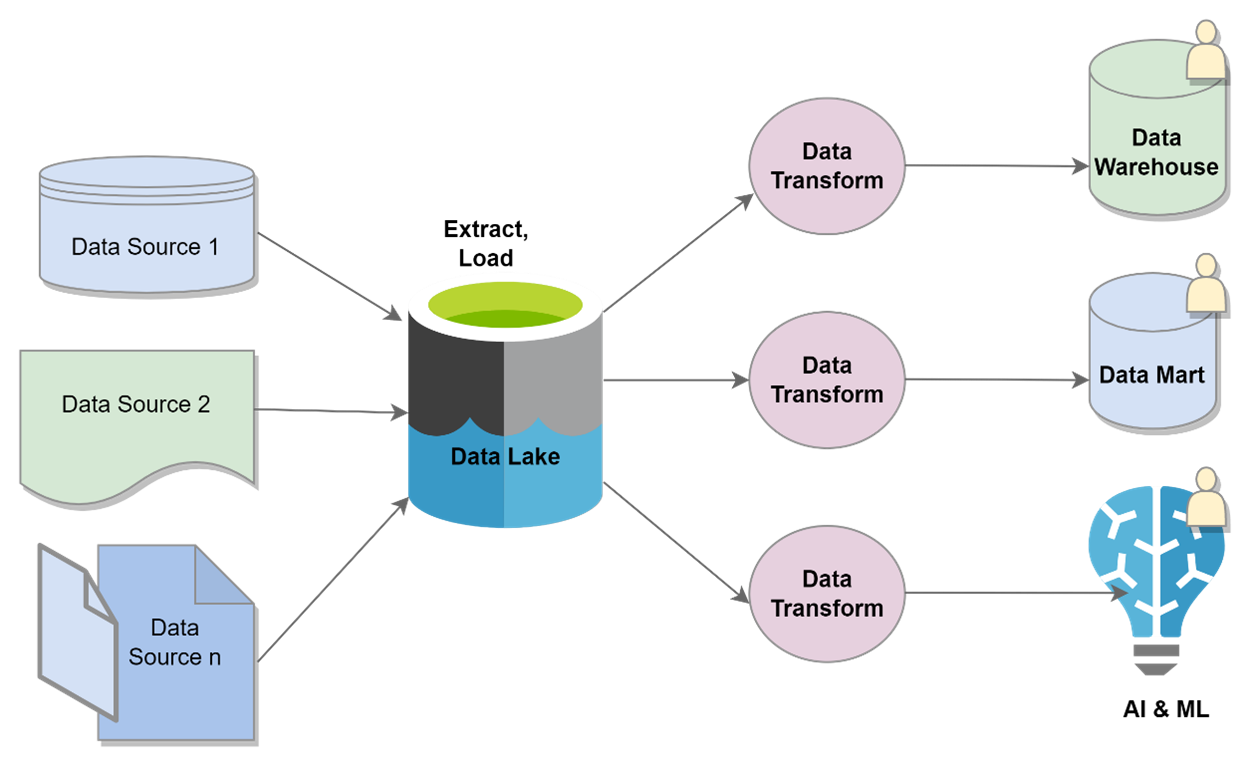
Here are some benefits of the data lake to consider:
- It contains consolidated data, both structured and unstructured.
- It provides the flexibility to store data in its original form.
- Compared to a data warehouse, it is cost-efficient in terms of operation and maintenance.
However, there are also a couple of downsides to the concept:
- The data in a data lake lacks consistency, which makes data security and reliability challenging to implement.
- Due to this lack of data consistency, the BI query performance can be suboptimal in a data lake.
The data lakehouse: a single platform to manage and analyse all your data?
Enter the data lakehouse which, as the name already suggests, combines the best attributes of both the data lake and the data warehouse. In a data lakehouse, the raw data consisting of structured and unstructured data is stored in a data lake. The data is then converted to a Delta Lake format, which is open-source software that extends Parquet data files with a file-based transaction log for ACID transactions and scalable metadata handling. ACID (which stands for data that is Atomic, Consistent, Isolated, and Durable) is a typical feature of a data warehouse which ensures the easy reading of data for analysis or business intelligence (BI).
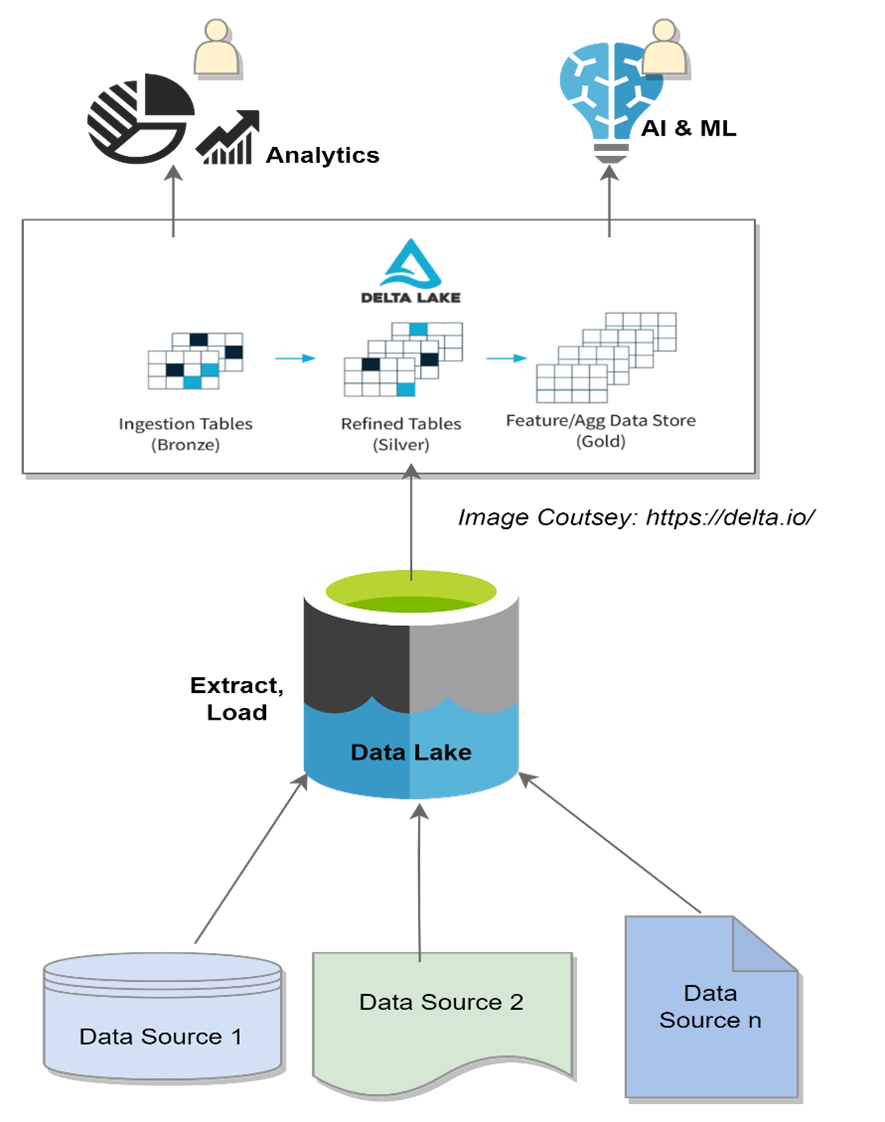
There are many benefits to working with a data lakehouse:
- A data lakehouse implements the cost-effective storage features of the data lake.
- It reduces data redundancy by providing a single data storage platform for all types of data.
- It is suitable for both data analytics and machine learning workloads.
- By enforcing data integrity, the data lakehouse architecture enables a better implementation of data security schemas than data lakes.
- The data lakehouse supports open storage formats, making it easily accessible through programming languages such as R and Python.
- It allows real-time reporting by supporting streaming analytics.
The only downside of the data lakehouse can be its tricky maintenance due to its monolithic architecture.
In conclusion
In the end, as always when it comes to choosing data storage, your choice should be based on your own specific use case. A data warehouse or data mart, for instance, is a good solution if you require a mature and structured data solution that focuses on BI and analytics. If, however, you require some cost-effective data storage to run data science workloads on unstructured data, then a data lake is the better option. Finally, for cases which require both advanced analytics and machine learning (ML) workloads to run on the data, a data lakehouse is clearly the best option.
Data management and analytics are two of our key service areas when it comes to leveraging new technologies to enhance your company’s performance. Contact me or my colleagues at Sopra Steria to find out how we can help you grasp this strategic challenge: divya.jyoti@soprasteria.com